Inteligencia Artificial – Redes Neuronales

Inteligencia artificial
Los primeros apartados tienen como objetivo acercarnos a la inteligencia artificial. Aunque dedicaremos especial interés a las redes neuronales artificiales, a las que nos referiremos como RNA. La idea es presentar los conceptos teóricos que han sido utilizados en el desarrollo del ejemplo práctico. Todo aquel que, o bien no tenga ganas, o bien ya las conozca, puede saltarse los apartados teóricos e ir directamente al primer apartado práctico titulado “Entorno de desarrollo”.
La inteligencia artificial también llamada inteligencia computacional, es la inteligencia exhibida por máquinas. No expondré las diferentes definiciones de inteligencia artificial, pero si haré la siguiente observación, ya que todas están relacionadas con la siguiente idea:
“Desarrollo de métodos y algoritmos que permitan comportarse a las computadoras de modo inteligente”.
En base a esta idea, podemos decir que para la existencia de la inteligencia artificial, son necesarios en primer lugar un mecanismo para soportarla (Hardware), y unas herramientas para desarrollar programas de inteligencia artificial (Software). En ciencias de la computación una máquina “inteligente” ideal es un agente racional flexible que percibe su entorno y lleva a cabo acciones que maximicen sus posibilidades de éxito en algún objetivo o tarea.
Nils J. Nillson definió los cuatro pilares básicos en los que se apoya la inteligencia artificial:
- Búsqueda del estado requerido en el conjunto de los estados producidos por las acciones posibles.
- Algoritmos genéticos: análogo al proceso de evolución de las cadenas de ADN.
- Redes neuronales artificiales (a las que dedicaremos este artículo): análogo al funcionamiento físico de cerebro de animales y humanos.
- Razonamiento mediante una lógica formal: análogo al pensamiento abstracto humano.
Stuart Russell y Peter Norvig clasifican los tipos de inteligencia artificial en:
- Sistemas que actúan como humanos: tratan de actuar como humanos, usando como modelo el comportamiento del hombre, como por ejemplo la robótica.
“El estudio de cómo hacer computadoras que hagan cosas que de momento, la gente hace mejor”
- Sistemas que piensan como humanos: tratan de emular el pensamiento humano, están relacionados con actividades de toma de decisiones, resolución de problemas y aprendizaje; un ejemplo son las redes neuronales.
“El esfuerzo por hacer a las computadoras pensar … máquinas con mentes en el sentido amplio y literal”
- Sistemas que piensan racionalmente: tratan de imitar o emular el pensamiento lógico racional del ser humano, mediante el estudio de los cálculos que hacen posible percibir, razonar y actuar; como por ejemplo los sistemas expertos.
“El estudio de las facultades mentales a través del estudio de modelos computacionales”
- Sistemas que actúan racionalmente: tratan de emular de forma racional el comportamiento humano, es decir, alcanzar unos objetivos dadas unas creencias; entre otros podemos destacar los agentes inteligentes.
“Un campo de estudio que busca explicar y emular el comportamiento inteligente en términos de procesos computaciones”
Redes neuronales
Las RNA, tienen como finalidad modelar la forma de procesamiento de la información de los sistemas nerviosos biológicos. Estas se caracterizan por:
- Tener una inclinación a adquirir el conocimiento a través de la experiencia, almacenado en el peso relativo de las conexiones interneuronales.
- Elevada plasticidad y adaptabilidad, cambian dinámicamente con el medio.
- Un alto nivel de tolerancia a fallas, pueden sufrir un daño y continuar teniendo un buen comportamiento.
- Ofrecer un comportamiento no lineal, ya que procesan información procedente de otros fenómenos no lineales.
Neurobiología
Antes de entrar a explicar cómo funciona una RNA, resulta conveniente conocer el funcionamiento de una red neuronal biológica. A modo de comparación, debemos saber que los eventos en un chip de silicio se realizan en nanosegundos, mientras que en una neurona el tiempo es del orden de milisegundos. Sin embargo esta lentitud se compensa con un número inmenso de neuronas con conexiones masivas entre ellas.
La mayoría de las neuronas codifican sus salidas como una serie de breves impulsos periódicos, llamados potenciales de acción, que se originan cercanos al soma de la célula y se propagan a través del axón. Este pulso llega a las sinapsis y de ahí a las dendritas de la neurona siguiente.
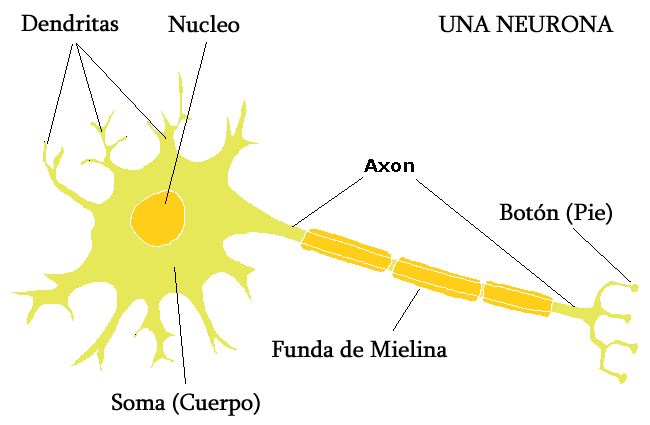
Una sinapsis es una interconexión entre dos neuronas. El tipo más común de sinapsis es la sinapsis química. En ella una señal neural eléctrica pre-sináptica, llega al botón sináptico. Allí, está hace que las vesículas sinápticas (en azul) se rompan, liberándose una sustancia llamada neurotransmisor. Esta sustancia química se difunde a través del espacio entre las neuronas. Luego es captada por la dendrita, en donde estimula la emisión de un nuevo impulso eléctrico, post-sináptico, que se propaga hacia la derecha.
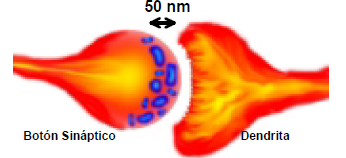
Hay dos comportamientos importantes en base a los cuales se construye una RNA.
- El impulso que llega a la sinapsis y el que sale no son iguales en general. El tipo de pulso dependerá de la cantidad de neurotransmisor. Además esta cantidad cambia durante el proceso de aprendizaje, ya sea reforzándose o debilitándose.
- En el soma se suman las entradas de todas las dendritas. Si sobrepasa un cierto umbral se transmitirá un pulso a lo largo del axón. Después de transmitir un impulso la neurona no puede transmitir durante un tiempo de entre 0,5 ms a 2 ms. A este tiempo se le llama período refractario.
Modelo neuronal
En este apartado se va a presentar un modelo sencillo de neurona, necesario para construir una RNA. El fin es modelar correctamente el comportamiento global de toda la red. Supongamos que tenemos una red sencilla como la de la siguiente imagen.
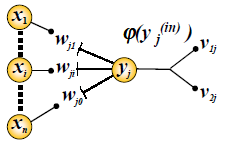
La neurona de interés es la Yj. Las N neuronas Xi están enviando señales de entradas que son los valores numéricos de algo. Estos valores Wji representan los pesos sinápticos en las dendritas de Yj. El primer índice de la notación utilizada denota a la neurona donde se dirige la información, y el segundo a la neurona del que procede. El peso sináptico multiplica a su entrada, definiendo la importancia relativa de cada entrada. De igual manera que ocurría en el soma de la neurona biológica se suman cada una de las entradas.
![]()
Donde (in) denota la entrada. La neurona se activará si la entrada total supera un cierto umbral, lo que se conoce como función de activación. Las neuronas y sus funciones de activación se dividen en dos tipos: bipolares o anti-simétricas y binarias. Si la función de activación de una neurona es lineal decimos que es una neurona lineal, sino diremos que es una neurona no lineal. Las neuronas lineales se representan normalmente por un cuadrado y las no lineales por un círculo. Una función de activación frecuentemente utilizada es la función sigmoidea, la cual se muestra a continuación.
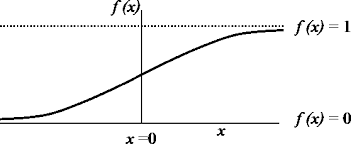
Resulta importante conocer el concepto de problemas linealmente separables. Estos problemas son aquellos para los que existe una línea recta, que delimita las entradas que hacen 0 la salida y las que la hacen 1. Otro concepto que debemos comprender es el de capa neural. Una capa neural representa ordenaciones de neuronas que poseen comportamientos similares. La capa de entrada no suele contabilizar. Si una red tiene más de una capa neural se la conoce como red multicapa. En estas redes las capas ocultas siempre son no lineales, además estas redes son capaces de resolver problemas más complejos, en detrimento de un proceso de aprendizaje más complejo.
Aprendizaje o entrenamiento
La información adquirida por una red neuronal se guarda en el valor de cada peso sináptico. El aprendizaje se divide en dos tipos, aprendizaje supervisado y no supervisado. En esta entrada únicamente se explica el aprendizaje supervisado, el cual se desarrolla mediante los siguientes pasos:
- Se dispone de un conjunto de N pares de entrenamiento. Donde se conocen tanto las entradas como las respuestas.
- Se introduce una de las entradas y se espera que la red responda.
- La red responde con una salida.
- Se compara la salida proporcionada por la red, con la salida correcta, creando una señal de error.
- Se corrige con la señal de error la sinapsis de la red mediante algún algoritmo.
A la secuencia completa de N pares de entrenamiento se le conoce como Época. El aprendizaje se detiene cuando la red responde correctamente a todos los pares de entrenamiento.
También es interesante conocer a lo que se llama Regla de Hebb. Hebb descubrió, que si dos neuronas a ambos lados de la sinapsis estaban activas o inactivas simultáneamente, entonces las sinapsis entre ellas se reforzaban, y si se activaban o desactivaban asincrónicamente se debilitaban.
Del mismo modo que existen redes unicapa y multicapa, existen métodos de aprendizaje para cada una de estas. Debido a que la mayoría de problemas no pueden resolverse con redes unicapa, únicamente veremos el aprendizaje en redes multicapa, en concreto el aprendizaje retropropagador de error. En general una RNA tiene la estructura de la siguiente figura, de la cual se dice que tiene L capas.
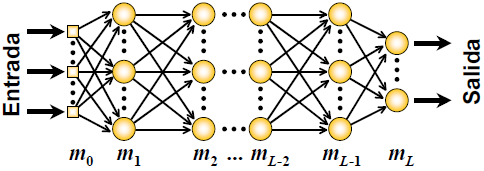
Existen dos tipos de señales:
- Señales de función: son el estímulo que entra en la capa 0, y pasa por cada capa del modo tradicional hasta la capa L, en donde se genera la señal de salida.
- Señales de error: cuando corregimos la sinapsis, las corregimos desde la capa L hacia la 0.
Como se ha dicho anteriormente vamos a explicar únicamente el funcionamiento del aprendizaje retropropagador de error, conocido en inglés por backpropagation error. El algoritmo emplea un ciclo de dos fases, durante la primera, se utiliza una señal de función, para generar una señal de salida. Una vez generada esta señal de salida, se compara con la salida deseada y se calcula una señal de error. La siguiente fase consiste en propagar hacia atrás la señal de error, con la peculiaridad de que las capas ocultas, solo reciben una fracción de la señal total de error. Esta fracción se basa en la contribución relativa al error total.
A medida que se repite el entrenamiento de la RNA, es decir se repite este ciclo, las neuronas de las capas intermedias ajustan sus pesos sinápticos. De esta forma serán capaces de reconocer patrones que se asemejen a aquellas características, que las neuronas individuales hayan aprendido a reconocer durante el entrenamiento.
Entorno de desarrollo
Para la realización del ejemplo práctico se han utilizado las siguientes versiones e IDE’s:
- Mars.1 Release 4.5.1.
- Java JDK 1.8.0_65.
- Maven.
- Encog 3.3.0
- JPA 2.1.
- Hibernate 5.2.10.
- MySQL 5.6.20.
Debido a que Encog es un framework que se sale un poco del uso común, voy hacer una breve introducción. Encog se encuentra disponible para Java, .Net, C++ e incluso JavaScript. En su repositorio encontraréis todo lo necesario para probarlo. La versión para Java podéis obtenerla del repositorio de Maven, aunque no creo que nadie lo dudara. Encog soporta multitud de algoritmos de aprendizaje y permite crear de una forma sencilla diferentes arquitecturas de RNA, además ofrece clases para el manejo y procesamiento de los datos.
Estructura del proyecto
Como en otras ocasiones, os recomiendo que bajéis el proyecto de GitLab. Una vez descargado y configurado deberíais tener una estructura como la de la siguiente imagen:
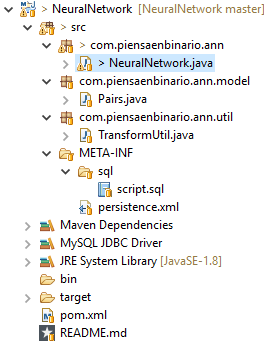
Básicamente el proyecto consiste en una aplicación de consola, conectada mediante JPA e Hibernate a una BBDD MySQL. En la BBDD están almacenados los pares de entrenamiento de la red, concretamente la tabla de verdad de una puerta XOR. Los datos se extraen de la BBDD y se mapean mediante la clase Pairs.java. La clase principal NeuralNetwork.java, se encarga de utilizar los datos para entrenar la red y realizar las predicciones. Debido a que los pares de entrenamiento deben tener un formato concreto se ha implementado la clase TansformUtil.java, encargada de transformarlos al formato adecuado.
Para facilitar la creación del proyecto, se incluye el script necesario para la creación del usuario, la base de datos, la tabla y los propios datos. Las dependencias a las librerías utilizas, se encuentran en el fichero pom.xml.
Construcción
En este apartado se describirá en primer lugar el modelo entidad relación, compuesto por una única tabla, y todo los necesario para manejarla. Y a continuación el código fuente implementado para hacer funcionar la RNA, comenzando por las clases utilizadas por la clase principal y acabando por esta misma.
Base de datos
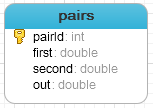
La única tabla del proyecto es la tabla “pairs”. Está compuesta por su clave primaria y tres campos double, que almacenan las entradas y la salida de los pares de entrenamiento utilizados para entrenar la red.
Eclipse provee un mecanismo por el cual se pueden generar de manera automática las clases persistentes de las entidades y la configuración con la BBDD. Para ello se debe seleccionar la opción de nuevo fichero y filtrar por JPA, entonces se mostrará la opción “JPA Entities from Tables”. El único requisito es que la BBDD debe estar creada previamente.
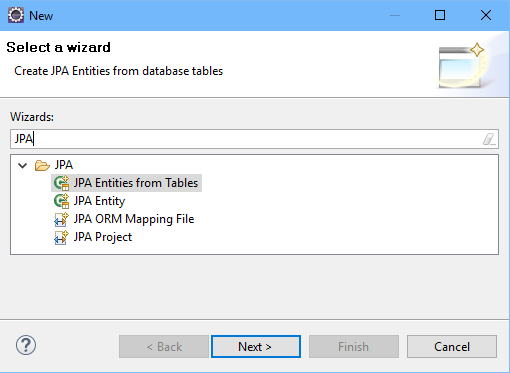
En nuestro caso la única clase persistente Pairs.java es la encarga de mapear la única tabla. Además, esta tiene los atributos y métodos necesarios para manejarla.
El fichero “persistence.xml” se encarga de conectar con la base de datos y de definir la entidad que vamos a gestionar.
<persistence-unit name="NeuralNetwork">
<class>com.piensaenbinario.ann.model.Pairs</class>
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/piensaenbinario_rna" />
<property name="javax.persistence.jdbc.user" value="ann" />
<property name="javax.persistence.jdbc.password" value="piensaenbinario_ann" />
</properties>
</persistence-unit>
TransformUtil.java
La clase TransformUtil.java está compuesta por dos métodos, ambos métodos reciben una lista de “Pairs”, pero difieren en su vuelta. Mientras que uno devuelve las entradas del entrenamiento, otro devuelve las salidas. A continuación se muestra a modo de ejemplo, el código fuente del método encargado de devolver las entradas.
public double[][] getDoubleMatrixInputs(List<Pairs> pairs){
double[][] matrix = new double[pairs.size()][2];
int f = 0;
for (Pairs pair : pairs) {
double[] file = new double[]{pair.getFirst(),pair.getSecond()};
matrix[f] = file;
f++;
}
return matrix;
}
En primer lugar es necesario inicializar una matriz de dimensiones Nx2, donde almacenar las entradas. A continuación recorremos cada uno de los pares de entrenamiento obtenidos de la BBDD. Creamos por cada uno, una nueva fila de la matriz, a partir de los atributos “first” y “second”. Finalmente una vez recorridos todos los pares se devuelve la matriz resultante.
NeuralNetwork.java
En primer lugar se crea el “EntityManagerFactory” que será único, ya que con él se pueden gestionar todas las entidades. Además se crea una instancia de la clase “TransformUtil” y se inicializan las matrices para los datos de entrada y salida respectivamente.
private static EntityManagerFactory factory = Persistence.createEntityManagerFactory("NeuralNetwork");
private static TransformUtil transform = new TransformUtil();
private static double XOR_INPUT[][];
private static double XOR_IDEAL[][];
A partir del EntityManagerFactory construimos un objeto de tipo EntityManager, encargado de gestionar un conjunto de entidades u objetos. Se realiza la query para traer los pares de entrenamiento y se transforman al formato correcto, para poder ser utilizados por la red.
EntityManager em = factory.createEntityManager();
Query q = em.createQuery("SELECT p FROM Pairs p");
List<Pairs> pairs = q.getResultList();
XOR_INPUT = transform.getDoubleMatrixInputs(pairs);
XOR_IDEAL = transform.getDoubleMatrixOutputs(pairs);
En este paso se crea la arquitectura de la red, la cual constará de dos capas, más la capa de entrada de datos. Tanto para la capa oculta como para la de salida, se utilizará como función de activación, una función sigmoidea. La capa de entrada consta de dos neuronas, la capa oculta de tres neuronas y la de salida, está formada de una única neurona.
BasicNetwork network = new BasicNetwork(); network.addLayer(new BasicLayer(null, true, 2)); network.addLayer(new BasicLayer(new ActivationSigmoid(), true, 3)); network.addLayer(new BasicLayer(new ActivationSigmoid(), false, 1)); network.getStructure().finalizeStructure(); network.reset();
Llegado a este punto, se comienza el entrenamiento de la red. En el código siguiente únicamente se muestra el entrenamiento mediante el algoritmo backpropagation error, sin embargo en el ejemplo completo se ofrece la posibilidad de elegir entre diferentes algoritmos, con el fin de observar la eficiencia de cada uno de ellos.
El proceso consiste en realizar tantas iteraciones como sean necesarias, hasta que el error a la hora de predecir la salida sea inferior a 0.0001. Recordar que cada una de estas iteraciones recibe el nombre de época.
MLDataSet training = new BasicMLDataSet(XOR_INPUT, XOR_IDEAL);
Train train = new Backpropagation(network, training);
do{
train.iteration();
}while( train.getError()>0.0001 );
Finalmente y una vez establecidos los pesos sinápticos de la red, llega el turno de realizar las predicciones para cada uno de los pares de entrenamiento y mostrar los resultados obtenidos.
for(MLDataPair pair:training){
final MLData output = network.compute(pair.getInput());
System.out.println(pair.getInput().getData(0) + "," + pair.getInput().getData(1) +", prediction=" + output.getData(0) + ", ideal=" + pair.getIdeal().getData(0));
}
Encog.getInstance().shutdown();
Código fuente
El código fuente de ejemplo se puede descargar desde Gitlab siguiendo el siguiente enlace.
https://gitlab.com/omaikyto/neuralnetwork.git
Referencias
Charniak, E., McDermott, 1985. Introduction to Artificial Intelligence. Addion Wesley Publishing Company.
Haugeland, J, 1985. Artificial Intelligence: The very idea by John Haugeland. MIT Press.
Izaurieta, F., Saavedra, C, 2000. Redes neuronales artificiales. Departamento de Física, Universidad de Concepción Chile.
Nillson N J, 1997. Artificial Intelligence: A New Synthesis. Morgan Kaufmann.
Norving S., Russel P, 2002. Artificial Intelligence: A Modern Approach (2nd Edition). Prentice Hall.
Rich, E., Knight, K, 1991. Artificial Intelligence. McGraw-Hill Publishing.
Schalkoff, R J, 1990. Artificial Intelligence: An Engineering Approach (Schaums Outline Series in Computers). Mcgraw-Hill College.
Wikipedia – Inteligencia artificial: https://es.wikipedia.org/wiki/Inteligencia_artificial
Tienes que estar conectado para dejar un comentario.